Python 导出公众号文章为 Markdown
记录一下个人使用 Python3 爬取个人公众号的所有文章,并把文章保存为 Markdown 格式的一些操作记录,主要介绍一下思路和一些简单的代码。
前提条件与思路¶
- 需要登录网页端微信公众号,获取对应 Cookies;
- 通过获取的 Cookies 爬取所有的文章 url 以及其他信息;
- 通过文章 url 获取对应文章的 HTML;
- 最后,把 HTML 转化为 Markdown。
之所以选择通过文章公开访问的 url 爬取对应文章的 HTML,而不是直接沿用 Cookies,主要是怕 Cookies 滥用导致其他不可预知的问题,例如封号之类。截止本文章发布前,个人公众号全部已发表的文章大约有 400 多篇,通过这个方法都能正常爬取下来。
获取已发表文章数¶
登录公众号,按下 F12 打开开发者工具,在 网络 栏中找到 appmsgpublish 名称的请求。
-
查看请求地址
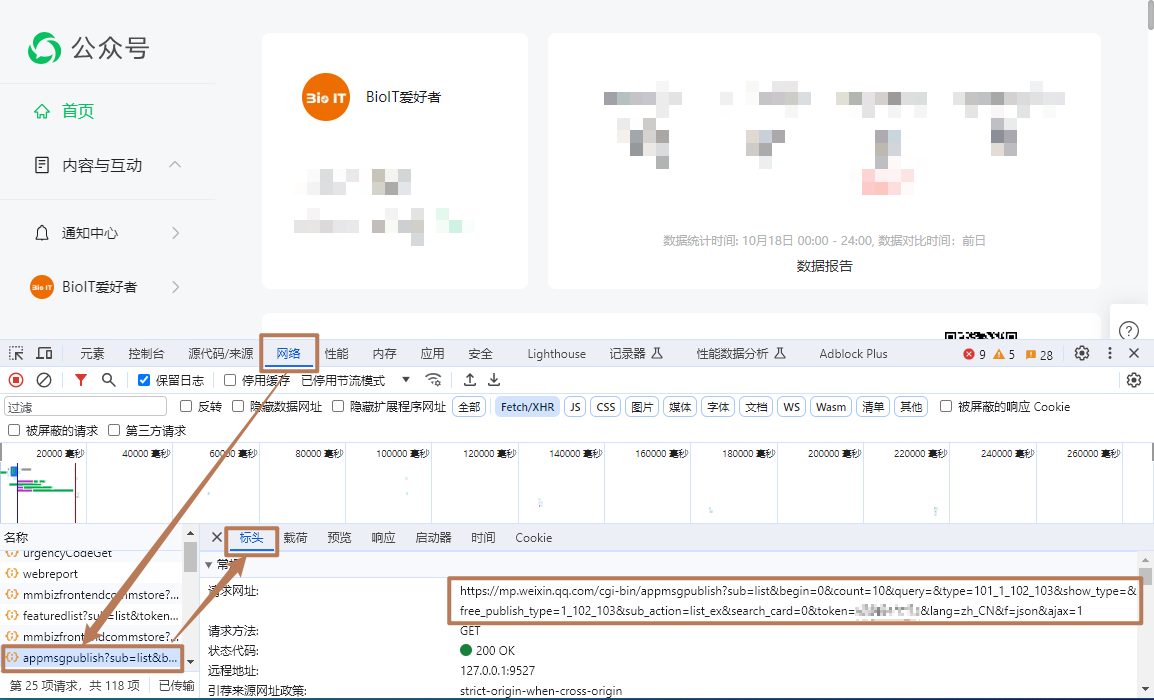
-
获取 cookie

import requests, json
#注意把 <Your Cookie> 替换成你自己的 cookie
headers = {'Content-type': 'application/json', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36',
'Cookie': <Your Cookie>}
#这个 url 即截图中的请求地址
url = 'https://mp.weixin.qq.com/cgi-bin/appmsgpublish?sub=list&search_field=null&begin=0&count=5&query=&type=101_1&free_publish_type=1&sub_action=list_ex&token=<token>&lang=zh_CN&f=json&ajax=1'
req = requests.get(url, headers=headers)
req_json = json.loads(req.content.decode("utf-8"))
req_json
# total_count 即为已发表文章的总数

获取所有的文章信息¶
以下程序的 mp.txt 就是得到的该公众号所有文章信息的列表。
allPostList = []
for number in range(0, 420, 20):
#注意 begin={number}&count=20,即按照每页20篇文章,分页进行爬取
#根据测试每页最多只支持20篇文章
url = f"https://mp.weixin.qq.com/cgi-bin/appmsgpublish?sub=list&search_field=null&begin={number}&count=20&query=&type=101_1&free_publish_type=1&sub_action=list_ex&token=<token>&lang=zh_CN&f=json&ajax=1', headers=headers)"
x = requests.get(url, headers=headers)
posts_list = json.loads(json.loads(x.content.decode("utf-8"))['publish_page'])["publish_list"]
allPostList = allPostList + posts_list
time.sleep(5)
with open("mp.txt", "w") as OUT:
OUT.write(str(allPostList))
HTML to Markdown¶
Python 导出公众号文章为 Markdown 最后的一步工作就是解析上一步骤得到的 mp.txt 文件,然后通过 url 去逐一爬取对应的文章 HTML,然后把 Html 转化成 Markdown 即可。
这些步骤都很简单,网上搜一下就有一大堆教程,感兴趣的可以去搜一下,这里文章就不写了。