扫描版与非扫描版 PDF 文字复制
许多影印版的 PDF 书籍资料,在阅读的时候都有一个让人很烦恼的问题:无法复制书中的文字内容!尤其这几天在阅读学习**《Python 数据可视化》(科斯·拉曼(Kirthi Raman) 著 )**这本书,想要记录一下学习笔记复制一些书中文字的时候,无法复制文字的问题简直让我忍无可忍。
Google 百度了一番,尝试了 Chrome 打开 PDF 后,在打印中另存为 PDF、Smallpdf 在线移除密码,以及其他的一些 PDF 解除加密都没有效果。后来才知道,原来我从经管之家使用 100 个论坛币下载的这本**《Python 数据可视化》**应该是一本影印版的 PDF 文件,而非加密的文档,一开始尝试 PDF 解除加密的解决方法方向本来就不对。应该变成如何从扫描版 PDF 文件中复制文字。
关于 PDF 扫描版与非扫描版,于是 Google 了一下,有这么个答案:
PDF 非扫描版就是直接转换的 PDF 文件,并且加了密。可以通过软件解密后编辑或转换。PDF 扫描版就是通过扫描仪扫描生成位图格式的 PDF 文件,并且加了密。此文件以图片形式存在,可以通过软件解密后要进行 OCR 识别后进行编辑文字。识别的好与坏要根据扫描的分辨率来确定。
扫描版与非扫描版 PDF 一般都可以单个文字选中复制修改,最大的区别是 PDF 文字版里面的文字是以矢量格式存储的,无论怎么放大都不会有锯齿或者失真的情况,而扫描版的 PDF 文件,在性质上属于位图格式的,文字是以图片的形式存储的,放大后会有失真或者严重的锯齿情况。
那么,回到原来的问题,扫描版的 PDF 如何复制里面的文字?我是参考了《Acrobat2018 怎么使用 OCR 识别扫描版 PDF 中的文字?》,完美解决了这个问题。
Acrobat 2017/2018 中不像之前的版本在编辑中能找到写有 OCR 功能的选项,那是因为 ocr 识别改名为“编辑文本和图像”了,下面我们就来看看 Acrobat2018 怎么使用 OCR 识别扫描版 PDF 中的文字教程。

1、打开要识别的 PDF,如果该 PDF 没有加密,那么点击“编辑-编辑文本和图像”或者在任意页面鼠标右击,选择“编辑图像”,就可以进行OCR 识别了。


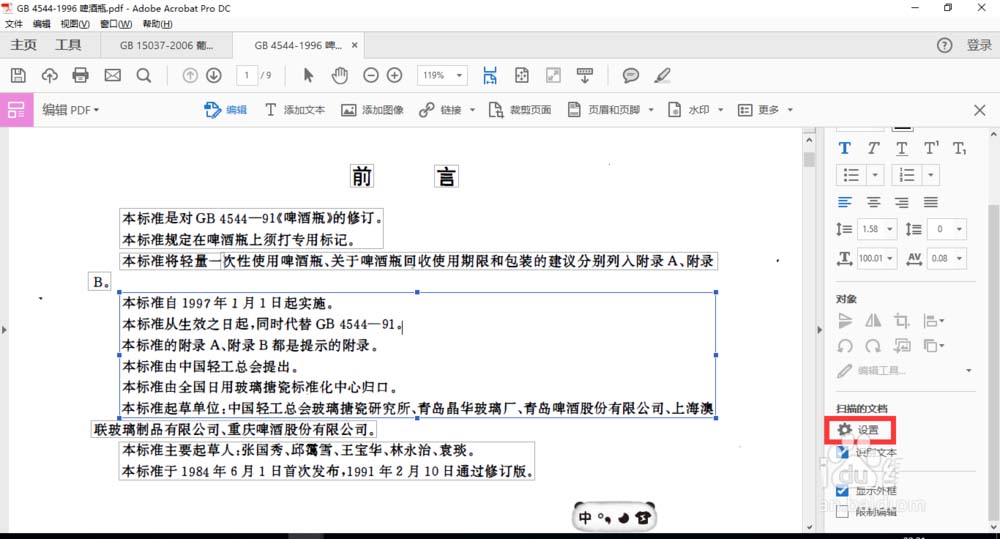
2、进行第一步之后,默认执行的单页的识别,但是如果你要识别整个 PDF 文件,怎么办?
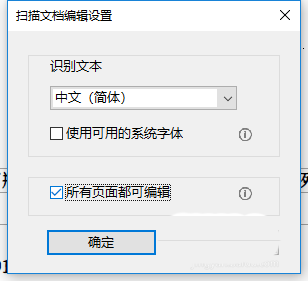
3、点击图中右下角扫描文档下的“**设置”,**在弹出的窗口中勾选“所有页面均可编辑”,点击确定,再点击编辑图像时,就可以全篇识别了。
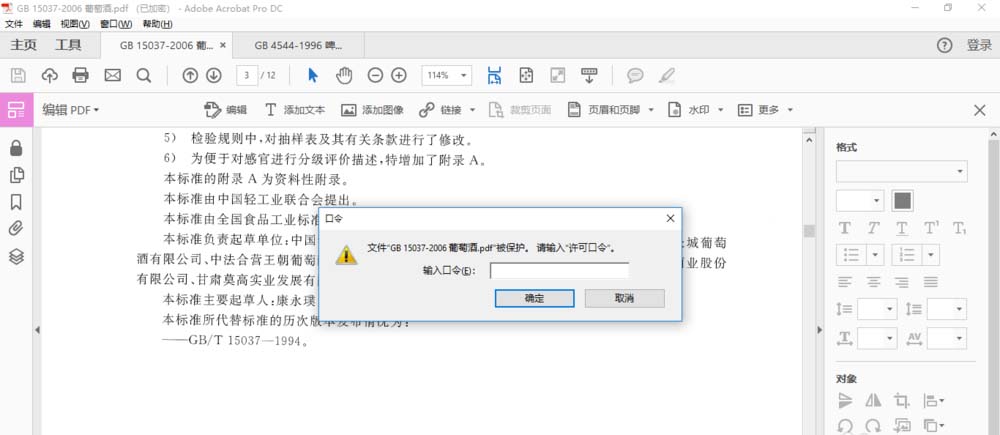
4、但是面对加密的文档,会提示需要“输入口令”,这个时候需要使用软件 PDFPasswordRmover,移除 PDF 的密码,就可以按照上面的方法愉快的 OCR 识别了。有时也会出现,点了“编辑图像”,但是未能进行 OCR 识别,只是把当页识别成一整张图片,我也用 PDFPasswordRmover 处理了一下,然后再进行 OCR 识别,就没问题了。
以上就是 Acrobat2018 找不到 OCR 识别的原因,直接使用编辑文本和图像也是一样的功能,希望大家喜欢。